Introduction
Hello my dear fellow humans, hope you are having a great day. Today’s guide is on how to recover from a disaster for Strimzi Kafka with Velero. First of all, what is Strmzi Kafka?
Strimzi provides a way to run an Apache Kafka cluster on Kubernetes in various deployment configurations.
![]()
Back in a while, I worked on Strimzi Kafka deployment on Openshift, very easy to set up and manage production-level Kafka cluster on Kubernetes, I have to give credit to the Strimzi project team, did a great job on documentation, support on Github discussions and active developments.
One of the important things in IT, when you bring new tech into a team, it should be disaster recovery proof. The team should be able to recover data and bring it back to a normal state after a disaster. For strimzi, it is very easy once you set up backend PV as dynamic storage class provisioner as you can 11.6. Recovering a cluster from persistent volumes. In this guide, I use the velero tool to make things automated and can easily set up in GitOps.
Heads-up ✋
Before dive into this guide, I want to make you aware of my existing setup and scope
- Strimzi Kafka stateful app is up and running on Kubernetes cluster with backend PV storage class provisioner as
AzureDisk. - Velero server up and running. Check my previous post “Velero Deployment with Kustomize (Azure)” to know how to set up.
- This guide does not cover basics of Kafka or how to set up Strimzi Kafka on kubernetes, head over to Strimzi Github project page and browse resources. But for the sake of this guide I create a demo repo containing Strimzi Kafka deployment files
Scenario
This is the simple test scenario I picked to test recovery steps. The test is to produce logs/messages to Kafka brokers and read the produced logs/messages from Kafka brokers after recovery. If the recovery is successful, the consumer should able to fetch logs/messages after recovery as you can see in the below diagram
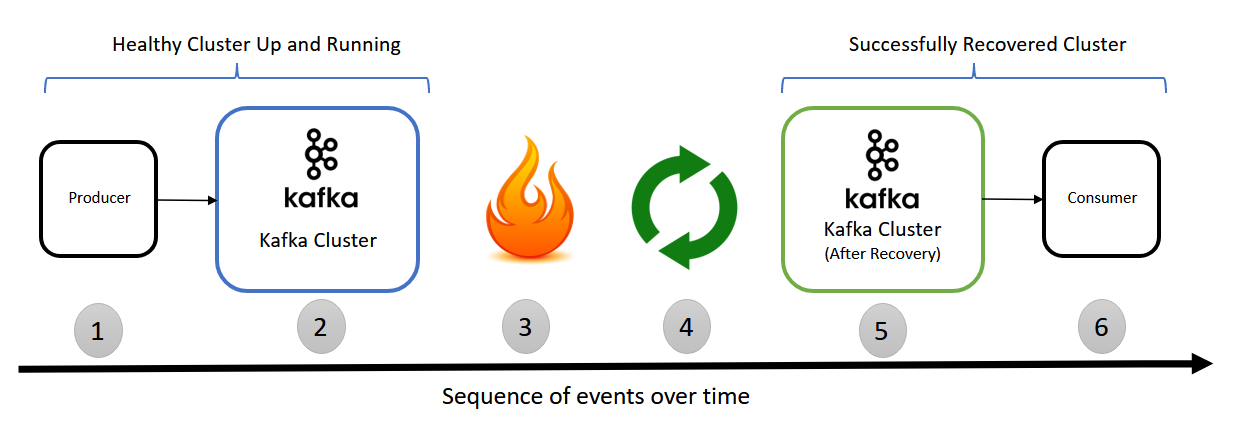
Assume below are events that happen over time.
- Producer produced some logs/messages to Kafka system
- Kafka brokers receives logs/messages and stores on disk
- Disaster happens(Refer “Disaster Simulation” to know how to simulate)
- Recovery (Refer “Recovery Plan” to know how to recover)
- Kafka recovered from disaster. Up and running
- Consumers now consume logs/messages which are produced in above point 1. If recovery is successful, the consumer should be able to fetch logs/messages there were stored in Kafka system before disaster.
Disaster Simulation
Before performing disaster simulation, Kafka cluster should be up and running, there should be some data generated on the cluster. In the prerequisites section, we will see how to prepare for disaster.
Cluster preparation
Velero CLI tool should be installed on your local machine.
$ git clone https://github.com/veerendra2/strimzi-kafka-demo $ cd strimzi-kafka-demo $ kubectl create -f base/namespace.yaml $ kubectl project kafka $ kubectl create -f base/cluster-operator.yaml $ kubectl create -f base/configmaps/ $ kubectl create -f stages/dev/deployment.yaml $ kubectl create -f stages/dev/topics.yaml $ kubectl create -f stages/dev/users.yamlWait until kafka cluster bootstrap and verify everything is running
$ kubectl get pods -n kafka NAME READY STATUS RESTARTS AGE carbon-dev-entity-operator-df5h6497-6xmqf 3/3 Running 0 4m carbon-dev-kafka-0 1/1 Running 0 6m carbon-dev-kafka-1 1/1 Running 0 6m carbon-dev-kafka-2 1/1 Running 0 6m carbon-dev-kafka-exporter-657956b4a-zpmdg 1/1 Running 0 3m carbon-dev-zookeeper-0 1/1 Running 0 7m carbon-dev-zookeeper-1 1/1 Running 0 7m carbon-dev-zookeeper-2 1/1 Running 0 7m strimzi-cluster-operator-658y5cf364-tw2nh 1/1 Running 0 2h $ kubectl get pvc -n kafka NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE data-0-carbon-dev-kafka-0 Bound pvc-8092d619-4883-11ec-9048-12rd2ab3g21f 256Gi RWO generic-retain 6m data-0-carbon-dev-kafka-1 Bound pvc-8093210e-4883-11ec-9048-12rd2ab3g21f 256Gi RWO generic-retain 6m data-0-carbon-dev-kafka-2 Bound pvc-8093c74a-4883-11ec-9048-12rd2ab3g21f 256Gi RWO generic-retain 6m data-carbon-dev-zookeeper-0 Bound pvc-4105d01a-4883-11ec-9048-12rd2ab3g21f 64Gi RWO generic-retain 7m data-carbon-dev-zookeeper-1 Bound pvc-4106f177-4883-11ec-9048-12rd2ab3g21f 64Gi RWO generic-retain 7m data-carbon-dev-zookeeper-2 Bound pvc-41072398-4883-11ec-9048-12rd2ab3g21f 64Gi RWO generic-retain 7m $ kubectl get kafkatopic -n kafka NAME CLUSTER PARTITIONS REPLICATION FACTOR my-topic carbon-dev 1 1 $ kubectl get kafkauser -n kafka NAME CLUSTER AUTHENTICATION AUTHORIZATION my-user carbon-dev tls simpleDeploy sample producer app to produce logs/messages to Kafka
## Check deployment config. For example, broker bootstrap route, topic name and user name. Deploy consumer test app $ kubectl create -f kafka-producer.yaml deployment.apps/java-kafka-producer created $ kubectl get pods -n kafka NAME READY STATUS RESTARTS AGE java-kafka-producer-bfd975945-cnmgg 0/1 Completed 1 42s carbon-dev-entity-operator-df5h6497-6xmqf 3/3 Running 0 4m carbon-dev-kafka-0 1/1 Running 0 6m carbon-dev-kafka-1 1/1 Running 0 6m carbon-dev-kafka-2 1/1 Running 0 6m carbon-dev-kafka-exporter-657956b4a-zpmdg 1/1 Running 0 3m carbon-dev-zookeeper-0 1/1 Running 0 7m carbon-dev-zookeeper-1 1/1 Running 0 7m carbon-dev-zookeeper-2 1/1 Running 0 7m strimzi-cluster-operator-658y5cf364-tw2nh 1/1 Running 0 2h $ kubectl logs java-kafka-producer-bfd975945-cnmgg -n kafka ... 2022-08-18 15:29:33 INFO KafkaProducerExample:69 - Sending messages "Hello world - 997" <<<<<<<<----------------THESE LOG LINES WE NEED TO LOOK TO KNOW PRODUCER SENT TO KAFKA 2022-08-18 15:29:33 INFO KafkaProducerExample:69 - Sending messages "Hello world - 998" 2022-08-18 15:29:33 INFO KafkaProducerExample:69 - Sending messages "Hello world - 999" 2022-08-18 15:29:33 INFO KafkaProducerExample:91 - 1000 messages sent ... 2994 [main] INFO org.apache.kafka.clients.producer.KafkaProducer - [Producer clientId=producer-1] Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms. 3008 [main] INFO org.apache.kafka.common.metrics.Metrics - Metrics scheduler closed 3008 [main] INFO org.apache.kafka.common.metrics.Metrics - Closing reporter org.apache.kafka.common.metrics.JmxReporter 3008 [main] INFO org.apache.kafka.common.metrics.Metrics - Metrics reporters closed 3009 [main] INFO org.apache.kafka.common.utils.AppInfoParser - App info kafka.producer for producer-1 unregistered [2022-08-18T15:29:33.852+0000] Heap [2022-08-18T15:29:33.852+0000] def new generation total 150016K, used 32262K [0x0000000619400000, 0x00000006236c0000, 0x00000006bb800000) [2022-08-18T15:29:33.852+0000] eden space 133376K, 24% used [0x0000000619400000, 0x000000061b3819d0, 0x0000000621640000) [2022-08-18T15:29:33.852+0000] from space 16640K, 0% used [0x0000000621640000, 0x0000000621640000, 0x0000000622680000) [2022-08-18T15:29:33.852+0000] to space 16640K, 0% used [0x0000000622680000, 0x0000000622680000, 0x00000006236c0000) [2022-08-18T15:29:33.852+0000] tenured generation total 333184K, used 7580K [0x00000006bb800000, 0x00000006cfd60000, 0x0000000800000000) [2022-08-18T15:29:33.852+0000] the space 333184K, 2% used [0x00000006bb800000, 0x00000006bbf672b0, 0x00000006bbf67400, 0x00000006cfd60000) [2022-08-18T15:29:33.852+0000] Metaspace used 23126K, capacity 23940K, committed 24192K, reserved 1071104K [2022-08-18T15:29:33.852+0000] class space used 2563K, capacity 2885K, committed 2944K, reserved 1048576K
Configure backup
Once Kafka is loaded with sample data, configure backup like below.
# Velero binary uses a local kubeconfig file to manage velero deployment. So, before running velero, login into cluster
# Run one time backup for the test scenario
$ velero backup create kafka-backup --include-namespaces=kafka --include-resources persistentvolumeclaims, persistentvolumes
Backup request "kafka-backup" submitted successfully.
Run `velero backup describe kafka-backup` or `velero backup logs kafka-backup` for more details.
## Verify backup is "Completed"
$ velero backup get
NAME STATUS CREATED EXPIRES STORAGE LOCATION SELECTOR
kafka-backup Completed 2021-11-21 21:25:23 +0100 STD 88d default <none>
Destroy
Delete kafka resources in kafka namespace
## Note down below PVs
$ kubectl get pvc -n kafka | awk '{print $3}' | tail -n+2
pvc-9aad8969-4afa-11ec-9048-12rd2ab3g21f
pvc-9aadbaf8-4afa-11ec-9048-12rd2ab3g21f
pvc-9aadd6b8-4afa-11ec-9048-12rd2ab3g21f
pvc-6d3118cf-4afa-11ec-9048-12rd2ab3g21f
pvc-6d3172c1-4afa-11ec-9048-12rd2ab3g21f
pvc-6d3176b9-4afa-11ec-9048-12rd2ab3g21f
## Delete kafka cluster, PVC and namesapce
$ kubectl delete kafka `kubectl get kafka -n kafka | awk '{print $1}' | tail -n+2`
$ kubectl delete pv `kubectl get pvc -n kafka | awk '{print $3}' | tail -n+2`
$ kubectl delete pvc `kubectl get pvc -n kafka | awk '{print $1}' | tail -n+2`
$ kubectl delete -f base/cluster-operator.yaml
$ kubectl delete namespace kafka
Delete disks in cloud provider portal UI to make disaster more solid if required
Recovery Steps
Preparation
- Velero CLI should be installed on your local machine (Refere Basic Install).
- All strimzi deployments files should be exactly the same as before the disaster.
Check which backups you want to restore
# Login into cluster
$ velero backup get
NAME STATUS CREATED EXPIRES STORAGE LOCATION SELECTOR
kafka-backup Completed 2021-11-21 21:25:23 +0100 STD 88d default <none>
Restore disk
In below example uses “kafka-backup” backup to restore from it
$ velero restore create --from-backup kafka-backup
Restore request "kafka-backup" submitted successfully.
Run `velero restore describe kafka-backup` or `velero restore logs kafka-backup` for more details.
# Wait until the restore completed
$ velero restore describe kafka-backup
Name: kafka-backup
Namespace: velero
Labels: <none>
Annotations: <none>
Phase: InProgress <<<<<<<<<<<<---STATUS
Backup: kafka-backup
Namespaces:
Included: all namespaces found in the backup
Excluded: <none>
Resources:
Included: *
Excluded: nodes, events, events.events.k8s.io, backups.velero.io, restores.velero.io, resticrepositories.velero.io
Cluster-scoped: auto
Namespace mappings: <none>
Label selector: <none>
Restore PVs: auto
Once restore is completed, check PVCs created.
❗ After restore completed, the PV “names” will same as during backup, but underneath the actual disk name is different in Azure cloud which you can see in below snippet
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-0-carbon-dev-kafka-0 Bound pvc-9aad8969-4afa-11ec-9048-12rd2ab3g21f 256Gi RWO generic-retain 3m
data-0-carbon-dev-kafka-1 Bound pvc-9aadbaf8-4afa-11ec-9048-12rd2ab3g21f 256Gi RWO generic-retain 3m
data-0-carbon-dev-kafka-2 Bound pvc-9aadd6b8-4afa-11ec-9048-12rd2ab3g21f 256Gi RWO generic-retain 3m
data-carbon-dev-zookeeper-0 Bound pvc-6d3118cf-4afa-11ec-9048-12rd2ab3g21f 64Gi RWO generic-retain 3m
data-carbon-dev-zookeeper-1 Bound pvc-6d3172c1-4afa-11ec-9048-12rd2ab3g21f 64Gi RWO generic-retain 3m
data-carbon-dev-zookeeper-2 Bound pvc-6d3176b9-4afa-11ec-9048-12rd2ab3g21f 64Gi RWO generic-retain 3m
$ kubectl describe pv pvc-9aad8969-4afa-11ec-9048-12rd2ab3g21f
Name: pvc-9aad8969-4afa-11ec-9048-12rd2ab3g21f
Labels: velero.io/backup-name=kafka-backup velero.io/restore-name=kafka-backup
Annotations: pv.kubernetes.io/bound-by-controller=yes pv.kubernetes.io/provisioned-by=kubernetes.io/azure-disk volumehelper.VolumeDynamicallyCreatedByKey=azure-disk-dynamic-provisioner
Finalizers: [kubernetes.io/pv-protection]
StorageClass: generic-retain
Status: Bound
Claim: kafka/data-0-carbon-dev-kafka-0
Reclaim Policy: Retain
Access Modes: RWO
Capacity: 256Gi
Node Affinity: <none>
Message:
Source:
Type: AzureDisk (an Azure Data Disk mount on the host and bind mount to the pod)
DiskName: restore-1b8257d7-2156-44ae-aa30-36f2gc6c64r6 ## <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<----DISK NAME IS DIFFERENT AFTER RESTORE
DiskURI: /subscriptions/fd667dc8-1e9e-4ab4-b428-9879d458e8ac/resourceGroups/carbondev-openshift/providers/Microsoft.Compute/disks/restore-1b8257d7-2156-44aeaa30-36f2gc6c64r6
Kind: Managed
FSType:
CachingMode: None
ReadOnly: false
Events: <none>
Re-deploy Strimzi Kafka to recover
From strimzi docs; 10.5.3. Recovering a deleted cluster from persistent volumes
You can recover a Kafka cluster from persistent volumes (PVs) if they are still present. You might want to do this, for example, after:
- A namespace was deleted unintentionally
- A whole Kubernetes cluster is lost, but the PVs remain in the infrastructure
In our deployment, we use jbod config, the generate PVC name should be data-0-[CLUSTER-NAME]-kafka-0
1. Bring up cluster-operator
$ git clone https://github.com/veerendra2/strimzi-kafka-demo
$ cd strimzi-kafka-demo
$ kubectl create -f base/namepsace.yaml
$ kubectl create -f base/cluster-operator.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
strimzi-cluster-operator-5c8d5cf966-dhhws 1/1 Running 0 2m
2. Deploy topics
⚠️ If you deploy
topic-operatorbefore deployingtopics, thetopic-operatordeletes existing topics while bootstrapping. That’s why we need to deploytopicsfirst
$ kubectl create -f stages/dev/topics.yaml
3. Deploy Kafka cluster and users
$ kubectl create -f stages/dev/deployment.yaml
kafka.kafka.strimzi.io/carbon-dev created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
carbon-dev-entity-operator-cd54f496-vmsfm 3/3 Running 0 3m
carbon-dev-kafka-0 1/1 Running 0 5m
carbon-dev-kafka-1 1/1 Running 0 5m
carbon-dev-kafka-2 1/1 Running 0 5m
carbon-dev-kafka-exporter-c67976b6b-vzdff 1/1 Running 0 3m
carbon-dev-zookeeper-0 1/1 Running 0 7m
carbon-dev-zookeeper-1 1/1 Running 0 7m
carbon-dev-zookeeper-2 1/1 Running 0 7m
strimzi-cluster-operator-5c8d5cf966-dfhwf 1/1 Running 0 10m
$ kubectl create -f stages/dev/users.yaml
# Verify all users and topics are created
$ kubectl get kafkatopic
NAME CLUSTER PARTITIONS REPLICATION FACTOR
my-topic carbon-dev 1 1
$ kubectl get kafkauser
NAME CLUSTER AUTHENTICATION AUTHORIZATION
my-user carbon-dev tls simple
If everything works well, the deployment should pick up existing PVCs and running!
Verification
👉 This verification is based on the scenario we picked.
In the above section “Disaster Simulation”, we deployed a sample producer java app to produce logs/messages into Kafka. Now in this step(after recovery), we fetch those logs/messages to see recovery was successful
# Check deployment config. For example, broker bootstrap route, topic name and user name. Deploy consumer test app
$ kubectl create -f kafka-consumer.yaml
deployment.apps/java-kafka-consumer created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
java-kafka-consumer-7456748dbc-vvftf 1/1 Running 0 37s
carbon-dev-entity-operator-cd54f496-vmsvm 3/3 Running 0 11m
carbon-dev-kafka-0 1/1 Running 0 4m
carbon-dev-kafka-1 1/1 Running 0 3m
carbon-dev-kafka-2 1/1 Running 0 3m
carbon-dev-kafka-exporter-c67976b6b-vz6f6 1/1 Running 0 10m
carbon-dev-zookeeper-0 1/1 Running 0 15m
carbon-dev-zookeeper-1 1/1 Running 0 15m
carbon-dev-zookeeper-2 1/1 Running 0 15m
strimzi-cluster-operator-5c8d5cf966-dhhws 1/1 Running 0 18m
## Check logs of the app, see it is fetching messages that were pushed before disaster
$ kubectl logs java-kafka-consumer-7456748dbc-vvftf
2021-11-23 02:59:28 INFO KafkaConsumerExample:49 - offset: 20891
2021-11-23 02:59:28 INFO KafkaConsumerExample:50 - value: "Hello world - 891"
2021-11-23 02:59:28 INFO KafkaConsumerExample:52 - headers:
2021-11-23 02:59:28 INFO KafkaConsumerExample:47 - Received message:
2021-11-23 02:59:28 INFO KafkaConsumerExample:48 - partition: 0
2021-11-23 02:59:28 INFO KafkaConsumerExample:49 - offset: 20892
2021-11-23 02:59:28 INFO KafkaConsumerExample:50 - value: "Hello world - 892"
2021-11-23 02:59:28 INFO KafkaConsumerExample:52 - headers:
2021-11-23 02:59:28 INFO KafkaConsumerExample:47 - Received message:
2021-11-23 02:59:28 INFO KafkaConsumerExample:48 - partition: 0
2021-11-23 02:59:28 INFO KafkaConsumerExample:49 - offset: 20893
2021-11-23 02:59:28 INFO KafkaConsumerExample:50 - value: "Hello world - 893"
2021-11-23 02:59:28 INFO KafkaConsumerExample:52 - headers:
2021-11-23 02:59:28 INFO KafkaConsumerExample:47 - Received message:
2021-11-23 02:59:28 INFO KafkaConsumerExample:48 - partition: 0
2021-11-23 02:59:28 INFO KafkaConsumerExample:49 - offset: 20894
2021-11-23 02:59:28 INFO KafkaConsumerExample:50 - value: "Hello world - 894"
2021-11-23 02:59:28 INFO KafkaConsumerExample:52 - headers:
2021-11-23 02:59:28 INFO KafkaConsumerExample:47 - Received message:
...
If you able to see output like above(hello message), the Strimzi Kafka is restored properly
Conclusion
In this guide, we have seen how to set up a disaster recovery plan for Strimzi Kafka by using a simple scenario and simulating disaster with Velero.