Introduction
Hello guys, today I came up with an interesting write-up, that is how to set up backup and restore with Velero on Kubernetes. A year back I worked on Strimzi Kafka, a deployment solution for deploying production-level Kafka on Kubernetes. Strimzi Kafka uses persistance volume(PV) as a disk which is a managed disk from a cloud provider(e.g. Azure, AWS, etc), but I couldn’t find a proper backup solution in order to configure PV backup and restore. Sure, you can configure these managed disk backups from Terraform or manually in cloud provider portals. But tools like Velero, backup PV from kubernetes side which is more visible and easy to manage which is what you will see in a moment.
❗ Velero supports multiple cloud provider, this write-up covers only deployment of Velero on kubernetes with storage class provisioner as
AzureDisk👉 All deployment files are in my repo https://github.com/veerendra2/velero-demo
Velero
![]()
Velero is an open source tool to safely backup and restore, perform disaster recovery, and migrate Kubernetes cluster resources and persistent volumes
- Disaster Recovery → Reduces time to recovery in case of infrastructure loss, data corruption, and or service outage
- Data Migration → Enables cluster portability by easily migrating Kubernetes resources from one cluster to another.
- Data Protection → Offers key data protection features such as scheduled backups, retention schedules, and pre or post-backup hooks for custom actions.
Features
- Backup Clusters Backup your Kubernetes resources and volumes for an entire cluster, or part of a cluster by using namespaces or label selectors.
- Schedule Backups Set schedules to automatically kickoff backups at recurring intervals.
- Backup Hooks Configure pre and post-backup hooks to perform custom operations before and after Velero backups.
How it works
Velero uses service principle to access cloud resources for managing backups of deployments on K8s. It supports various plugins for the cloud, while deploying Velero we have to specify the plugin and provide credentials(/base/deployment.yaml#L67). By using Velero, we can backup deployments, PVs, namespaces and entire clusters.
- For deployment related backups, it uses storage account to store all deployments metadata
- For PV backup, it uses a snapshot from the cloud provider.
⚠️ Backups may fail sometimes if it doesn’t have necessary memory(#3234)
The below diagram gives a bird’s eye view of how Velero works
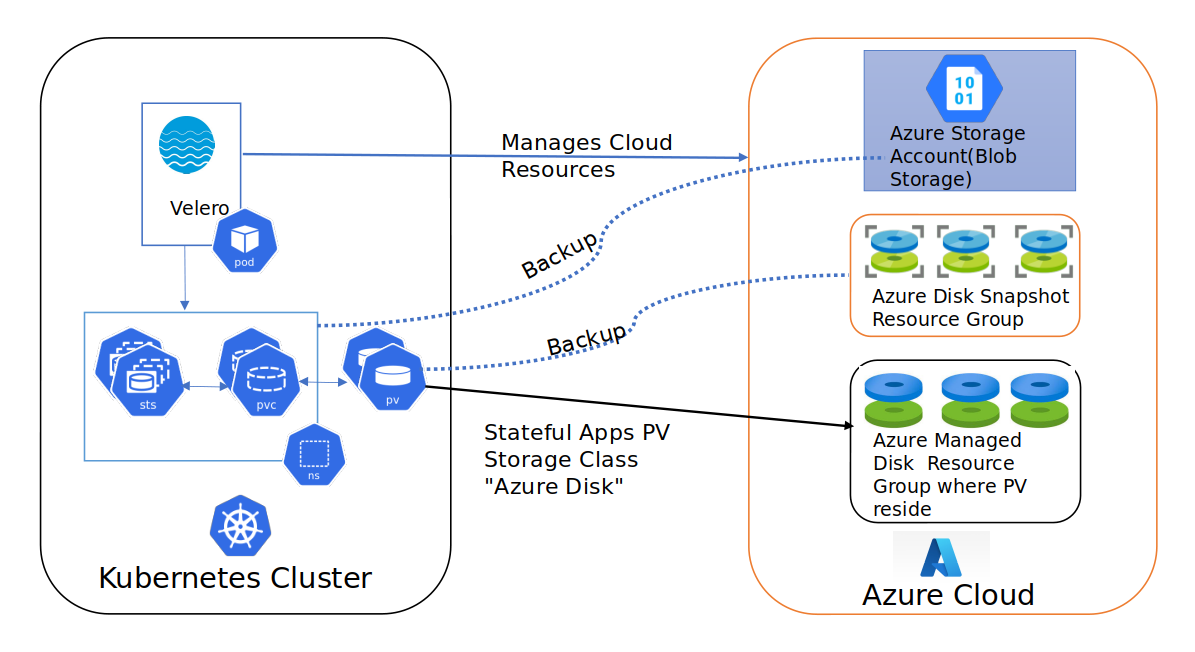
Deploy
Velero provides binary to manage velero server deployment and scheduled backups. But, in our deployment, we do something different, that is; use kustomize and manage in git repo. But first we need to download velero binary from release page here
$ curl -O https://github.com/vmware-tanzu/velero/releases/download/v1.9.1/velero-v1.9.1-linux-amd64.tar.gz
$ tar -xf velero-v1.9.1-linux-amd64.tar.gz
$ cd velero-v1.9.1-linux-amd64/
$ ls
examples LICENSE velero
$ sudo mv velero /usr/local/bin/
Prerequisites
Before deploying Velero server on kubernetes, we need to customize the velero server according to our needs. Below is the configuration for Velero to manage Azure resources.
Below are the variables that will be used during installation
| Environmental Variable Name | Description |
|---|---|
| SUBSCRIPTION_ID | Subscription ID |
| TENANT_ID | Tenant ID of service principle |
| CLIENT_ID | Client ID of service principle |
| CLIENT_SECRET | Service principal secret |
| RESOURCE_GROUP | Source resource groups where K8s PVs(Azure Managed Disks) are present to backup |
| BACKUP_RESOURCE_GROUP | Destination resource group where PV(Azure Managed Disks)snapshots are stored |
| STORAGE_ACCOUNT_ID | Storage account name |
| BLOB_CONTAINER | Container name in storage account where K8s deployment metadata stored |
| BACKUP_SUBSCRIPTION_ID | Subscription ID where backs are stored(In our case, this value SUBSCRIPTION_ID) |
| STORAGE_ACCOUNT_ACCESS_KEY | Storage account access key |
| CLOUD_NAME | Cloud name, the value is AzurePublicCloud |
Create service principal
$ az account list --query "[].{name:name, id:id}" --output tsv
$ export SUBSCRIPTION_ID="[SUBSCRIPTION_ID_HERE]"
$ az login
$ CLIENT_SECRET=`az ad sp create-for-rbac --name "velero-sp" --role"Contributor" --query 'password' -o tsv --scopes subscriptions/$SUBSCRIPTION_ID`
$ CLIENT_ID=`az ad sp list --display-name "velero-sp" --query'[0].appId' -o tsv`
$ TENANT_ID=`az ad sp list --display-name "velero-sp" --query"[].appOwnerTenantId" -o tsv
Create Azure storage account
$ az storage account create \
--name $STORAGE_ACCOUNT_ID \
--resource-group $RESOURCE_GROUP \
--location <location> \
--sku Standard_ZRS \
--encryption-services blob
$ az storage container create \
--account-name STORAGE_ACCOUNT_ID \
--name $BLOB_CONTAINER \
--auth-mode login
Set variables
Below are dummy values of variables.
$ cat << EOF > ./credentials-velero
SUBSCRIPTION_ID="my-sub-id"
TENANT_ID="my-tnt-id"
CLIENT_ID="my-client-id"
CLIENT_SECRET="secure-secret"
RESOURCE_GROUP="myresgrp"
CLOUD_NAME=AzurePublicCloud
EOF
$ export BACKUP_RESOURCE_GROUP=myresgrp
$ export STORAGE_ACCOUNT_ID=myaccount
$ export BACKUP_SUBSCRIPTION_ID=my-sub-id
$ export BLOB_CONTAINER=backup
Generate Deployment Files
Once variables are set and verified, generate velero deployment files using velero cli
❗ You can also get the velero deployment here
$ velero install \
--provider azure \
--plugins velero/velero-plugin-for-microsoft-azure:v1.1.0 \
--bucket $BLOB_CONTAINER \
--secret-file ./credentials-velero \
--backup-location-config resourceGroup=$BACKUP_RESOURCE_GROUP,storageAccount=$STORAGE_ACCOUNT_ID,subscriptionId=$BACKUP_SUBSCRIPTION_ID \
--snapshot-location-config apiTimeout=5m,resourceGroup=$BACKUP_RESOURCE_GROUP,subscriptionId=$BACKUP
_SUBSCRIPTION_ID \
--use-volume-snapshots=true
--dry-run -o yaml
...
Once you run the above command, it displays deployment files on stdout, because of the --dry-run -o yaml option. Copy the content to separate yaml files like below.
👉 You can check here how I seperated https://github.com/veerendra2/velero-demo/tree/main/base
## https://github.com/veerendra2/velero-demo/tree/main/base
$ tree .
.
├── cluster-role-binding.yaml
├── deployment.yaml
└── velero-crds.yaml
0 directories, 3 files
Once all files are arranged(and verify variables in below deployment files that we configured in above section), login into kubernetes and run the deployment one-by-one
$ kubectl create -f velero-crds.yaml
$ kubectl create -f cluster-role-binding.yaml
$ kubectl create -f deployment.yaml
Kubernetes deploys the velero server in the velero namespace as a pod. Verify velero server is installed with kubectl get pods -n velero
Configure Backups
We can configure backups with velero cli
❗ A handy tool to write cronjob -> https://crontab.guru/
$ velero schedule create kafka-backup-schedule \
--schedule="@every 168h" --ttl 2160h0m0s \
--include-namespaces=kafka
$ velero schedule get
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kafka-backup-schedule Enabled 2020-11-21 20:35:04 +0100 STD 0 15 * * 5 2160h0m0s 1d
ago <none>
The above example, backups all resources in namespace kafka(including PVs and K8s deployment files) for every 168 hours. But we want setup every thing in yaml files so that we store in git repo(e.g. /overlay/dev). So, we can ask velero cli to display yaml like below
$ velero schedule create kafka-backup-schedule --schedule="@every 168h" --ttl
2160h0m0s--include-namespaces=kafka -o yaml
apiVersion: velero.io/v1
kind: Schedule
metadata:
creationTimestamp: null
name: kafka-backup-schedule
namespace: kafka
spec:
schedule: '@every 168h'
template:
hooks: {}
includeClusterResources: true
includedNamespaces:
- '*'
ttl: 2160h0m0s
status: {}
You can also look for help like below
$ velero schedule create --help
The --schedule flag is required, in cron notation, using UTC time:
| Character Position | Character Period | Acceptable Values |
| ------------------ | :--------------: | ----------------: |
| 1 | Minute | 0-59,* |
| 2 | Hour | 0-23,* |
| 3 | Day of Month | 1-31,* |
| 4 | Month | 1-12,* |
| 5 | Day of Week | 0-7,* |
The schedule can also be expressed using "@every <duration>" syntax. The duration
can be specified using a combination of seconds (s), minutes (m), and hours (h), for
example: "@every 2h30m".
Usage:
velero schedule create NAME --schedule [flags]
We can get backup status if the schedule that we configured above.
$ velero schedule get
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kafka-backup-schedule Enabled 2020-11-21 20:35:04 +0100 STD 0 15 * * 5 2160h0m0s 1d
ago <none>
$ velero backup get
NAME STATUS CREATED EXPIRES STORAGE LOCATION SELECTOR
kafka-backup-schedule-20201121202523 Completed 2020-11-21 21:25:23 +0100 STD 88d
default <none>
kafka-backup-schedule-20201121201523 Completed 2020-11-21 21:15:23 +0100 STD 88d
default <none>
❗
scheduleconsists of multiplebackupas you can see above
Once everything is setup we can do magic with kustomize. So, below is finally show off with kustomize. This kustomize setup is very useful when you configure with GitOps tools like Argo CD.
👉 You can find this demo deployment files in my repo here https://github.com/veerendra2/velero-demo
$ tree .
.
├── base
│ ├── cluster-role-binding.yaml
│ ├── deployment.yaml
│ ├── kustomization.yaml
│ └── velero-crds.yaml
├── overlay
│ └── dev
│ ├── backup-locations.yaml
│ ├── backup-schedules
│ │ └── pvc.yaml
│ ├── kustomization.yaml
│ └── secrets
│ └── cloud-credentials.yaml
└── README.md
5 directories, 9 files
Terminology
Before concluding this write up, we need to get familiar with 2 terminologies that helps us to understand how Velero works internally
Backup Storage Location
The BackupStorageLocation holds info about storage account, container in storage account. We can have multiple “Backup Storage Location” with difference containers and storage account(e.g. dev/backup-locations.yaml#L2-L15)
## Since there velero CRDs are installed, we can query like below
$ kubectl get backupstoragelocations -n velero
NAME AGE
default 1d
kafka 1d
Volume Snapshot Location
The VolumeStorageLocation holds info about resource group where snapshots are stored(e.g. dev/backup-locations.yaml#L17-L21)
## Since there velero CRDs are installed, we can query like below
$ kubectl get volumesnapshotlocations -n velero
NAME AGE
default 1d
Restore
What good is the backup if you can’t restore?!…
Get schedule and backup like below
## Login into kubernetes with kubectl cli
$ velero schedule get
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kafka-backup-schedule Enabled 2020-11-21 20:35:04 +0100 STD 0 15 * * 5 2160h0m0s 1d
ago <none>
$ velero backup get
NAME STATUS CREATED EXPIRES STORAGE LOCATION SELECTOR
kafka-backup-schedule-20201121202523 Completed 2020-11-21 21:25:23 +0100 STD 88d
default <none>
Create restore
$ velero restore create --from-backup kafka-backup-schedule-20201121202523
Restore request "kafka-backup-schedule-20201121202523-20201123033701" submitted
successfully.
Run `velero restore describe kafka-backup-schedule-20201121202523-20201123033701` or
`velero restore logs kafka-backup-schedule-20201121202523-20201123033701` for more
details.
We can also describe to know the status
$ velero restore describe kafka-backup-schedule-20201121202523-20201123033701
Name: kafka-backup-schedule-20201121202523-20201123033701
Namespace: velero
Labels: <none>
Annotations: <none>
Phase: InProgress <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<----STATUS-HERE
Backup: kafka-backup-schedule-20201121202523
Namespaces:
Included: all namespaces found in the backup
Excluded: <none>
Resources:
Included: *
Excluded: nodes, events, events.events.k8s.io, backups.velero.io, restores.velero.io,
resticrepositories.velero.io
Cluster-scoped: auto
Namespace mappings: <none>
Label selector: <none>
Restore PVs: auto
Once restore is completed, verify has it been restored
$ kubectl get pods -n kafka
...
Conclusion
In this write up, I have covered
- Sneak peek on Velero
- How Velero works
- How to deploy and configure to manage resources on Azure.
- Configure scheduled backups
- Restore
- BONUS; I have collected handfull of
velerocli example in my Github gist here
Stay tuned, my next write-up will be published very soon which is related to backup and restore on Kubernetes 😃